Arm processors, used in Raspberry Pi’s and maybe even in a future Mac, are gaining in popularity due to their reduced cost and improved power efficiency over more traditional x86 offerings. As Arm processor adoption accelerates the need for Docker images that support both x86 and Arm will become more and more a necessity. Luckily, recent releases of Docker are capable of building images for multiple architectures. In this post I will cover one way to achieve this by combining a recent release of Gitlab (12+), k3s and the buildx plugin for Docker.
I am taking inspiration for this post from two places. First, this excellent writeup was a great help in getting things start – https://dev.to/jdrouet/multi-arch-images-with-docker-152f. This post was also instrumental in getting this going – https://medium.com/@artur.klauser/building-multi-architecture-docker-images-with-buildx-27d80f7e2408.
I assume you already have a working installation of Gitlab with the container registry configured. Optionally, you can use Docker Hub but I won’t cover that in detail. Using Docker Hub involves changing the repository URL and then logging into Docker Hub. You will also need some system available capable of running k3s that is using at least Linux 4.15+. For this you can use either Ubuntu 18.04+ or CentOS 8. There may be other options but I know these two will work. The kernel version is a hard requirement and is something that caused me some headache. If I had just RTFM I could have saved myself some time. For my setup I installed k3s onto a CentOS 8 VM and then connected it to Gitlab. For information on how to setup k3s and connecting it to Gitlab please see this post.
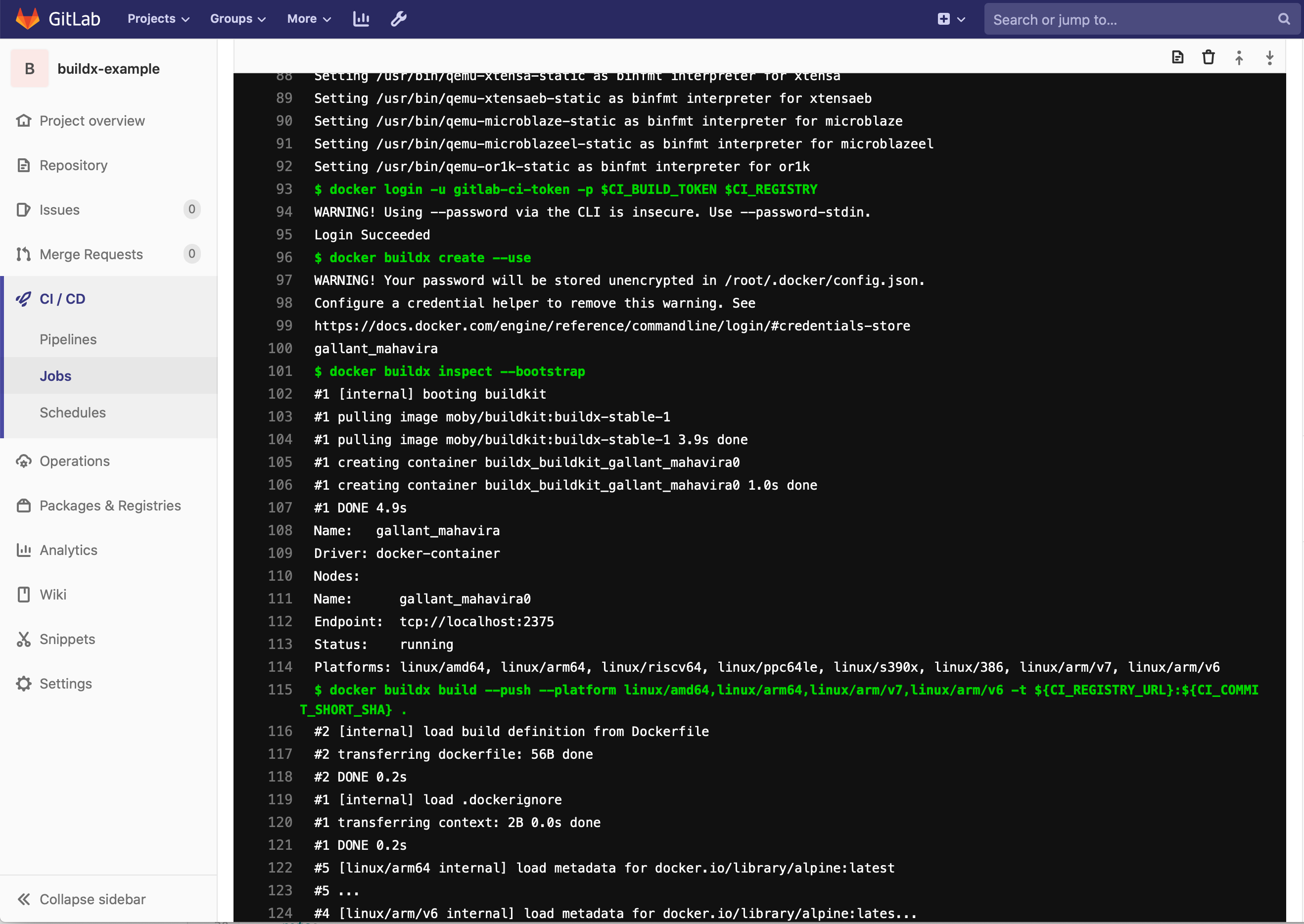
Once you are running k3s on a system with a supported kernel you can start building multi-arch images using buildx. I have created an example project available at https://github.com/dustinrue/buildx-example that you can import into Gitlab to get you started. This example project targets a runner tagged as kubernetes to perform the build. Here is a breakdown of what the .gitlab-ci.yml file is doing:
- Installs buildx from GitHub (https://github.com/docker/buildx) as a Docker cli plugin
- Registers qemu binaries to emulate whatever platform you request
- Builds the images for the requested platforms
- Pushes resulting images up to the Gitlab Docker Registry
Unlike the linked to posts I also had to add in a docker buildx inspect --bootstrap to make things work properly. Without this the new context was never active and the builds would fail.
The example .gitlab-ci.yml builds multiple architectures. You can request what architectures to build using the --platform flag. This command, docker buildx build --push --platform linux/amd64,linux/arm64,linux/arm/v7,linux/arm/v6 -t ${CI_REGISTRY_URL}:${CI_COMMIT_SHORT_SHA} . will cause images to be build for the listed architectures. If you need a list of available architectures you can target you can add docker buildx ls right before the build command to see a list of supported architectures.
Once the build has completed you can validate everything using docker manifest inspect. Most likely you will need to enable experimental features for your client. Your command will look similar to this DOCKER_CLI_EXPERIMENTAL=enabled docker manifest inspect <REGISTRY_URL>/drue/buildx-example:9ae6e4fb. Be sure to replace the path to the image with your image. Your output will look similar to this if everything worked properly:
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 527,
"digest": "sha256:611e6c65d9b4da5ce9f2b1cd0922f7cf8b5ef78b8f7d6d7c02f793c97251ce6b",
"platform": {
"architecture": "amd64",
"os": "linux"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 527,
"digest": "sha256:6a85417fda08d90b7e3e58630e5281a6737703651270fa59e99fdc8c50a0d2e5",
"platform": {
"architecture": "arm64",
"os": "linux"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 527,
"digest": "sha256:30c58a067e691c51e91b801348905a724c59fecead96e645693b561456c0a1a8",
"platform": {
"architecture": "arm",
"os": "linux",
"variant": "v7"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 527,
"digest": "sha256:3243e1f1e55934547d74803804fe3d595f121dd7f09b7c87053384d516c1816a",
"platform": {
"architecture": "arm",
"os": "linux",
"variant": "v6"
}
}
]
}
You should see multiple architectures listed.
I hope this is enough to get you up and running building multi-arch Docker images. If you have any questions please open an issue on Github and I’ll try to get it answered.