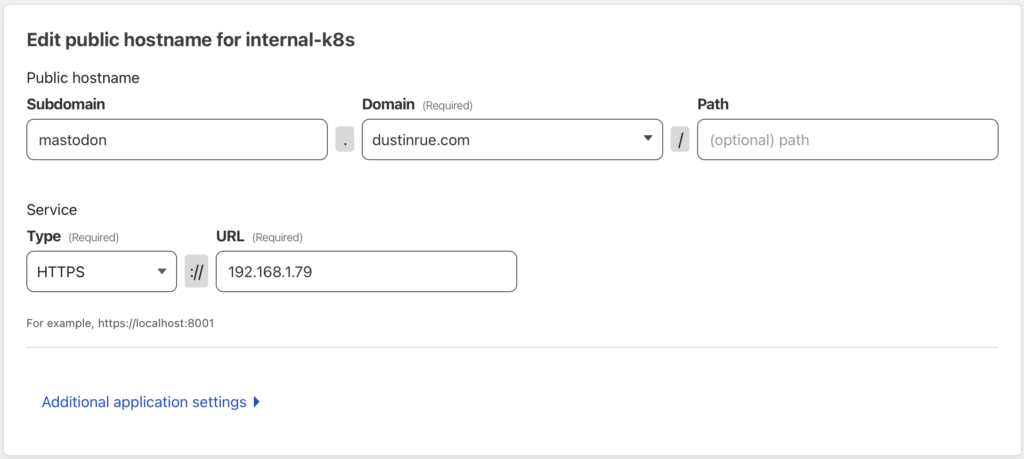
Yesterday I was reminded that when a URL is shared on Mastodon, every instance that has a user following you, that server will make a request to your site at least once in an effort to get some additional embed information. If your site is WordPress based, like this one, then you will likely see two requests. The first request to your site will request the URL that was added to the post while the second one follows any embed information WordPress is exposing in order to get some additional meta data. Since Mastodon is a federated system, every Mastodon server or instance will need to gather this data in order for it to be displayed to its users.
If you are a user that has a lot of followers then posting a link to your blog or site will likely result in a mini DDoS has hundreds of Mastodon instances request this information from your server. If you have not taken precautions this can potentially take down your site as it is overloaded with requests! Years ago this would have been referred to as being “slash dotted” (links on https://slashdot.org) or “fireballed” (links on https://daringfireball.net).
Fortunately you can very effectively deal with this situation on your own or by working with your hosting provider. In this post, I am going to describe how I handle the situation using Cloudflare, which is the CDN provider I have chosen to put my site behind. I am not going into full detail on how to implement all options and I am not selling Cloudflare or associated with them beyond being a customer. What I share here will be applicable to any CDN or will at least serve as inspiration for how to handle it in your configuration.
As I said previously, this site is using WordPress and is behind Cloudflare. To make it easy on myself I have also purchased their Automatic Platform Optimization for WordPress feature. I got into this option initially because I wanted to understand it better but have since kept it because it works well. The biggest feature of APO for WordPress is that it enables full page caching for your site. This is a must if you want to get the best possible experience for users globally. Using APO is absolutely not necessary, you can simply use Nginx micro caching instead or any other caching solution, but the key here is to have full page caching so that repeated requests to your site do not incur actual processing time by WordPress.
APO will, out of the box, cache full pages of your site but what it will not protect is the meta data URL used to provide additional information for embeds. To prevent Mastodon servers from crushing your site with embed meta data requests, there is one additional endpoint you need to force to be cached. Here is how I forced Cloudflare to cache the correct URL for me.
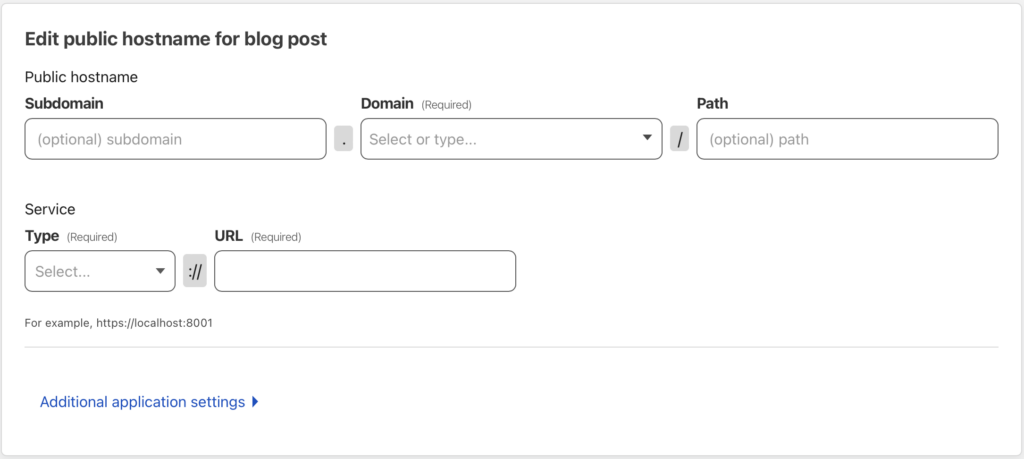
Login into Cloudflare and click on the domain for your site. Find the caching section of the menu and click on Cache Rules. Add a new rule and define what is shown in the screenshot
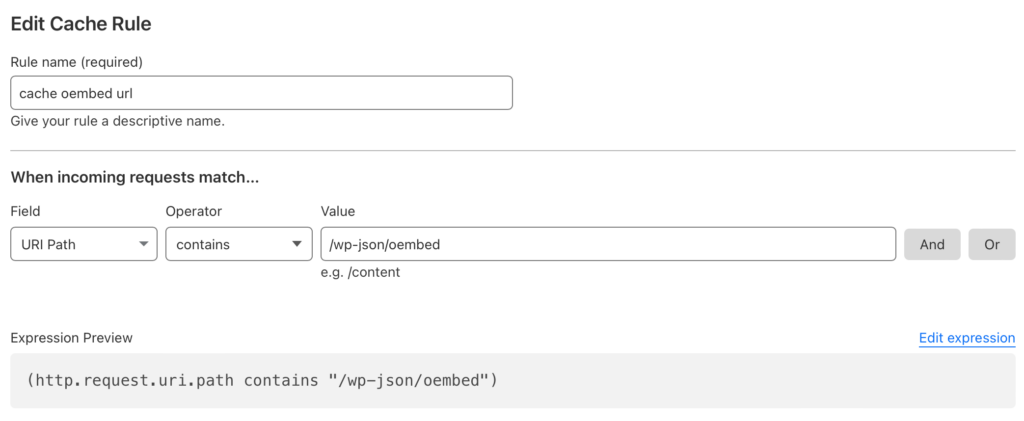
From here, tell Cloudflare what to do with this match
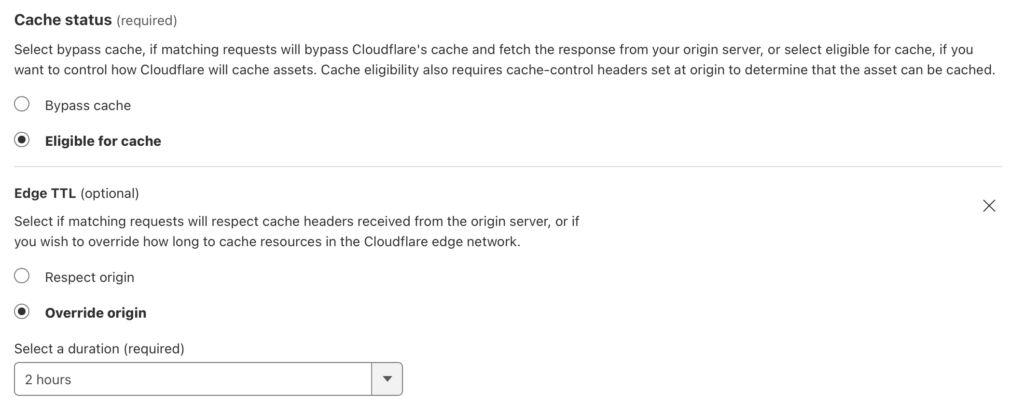
Note that 2 hours is the lowest cache time I can specify on an otherwise free Cloudflare plan so that is what I set it to. With these options filled out you can click save and you are done. Anything looking for this URL will now either get a cached copy of the response or will cause the content to be cached for future requests.
Of course, you don’t need to use Cloudflare to make this work. Savvy users can also translate these URLs to Nginx or Apache configuration to perform the trick. The goal is to ensure your WordPress site is better able to handle when you have shared a link to Mastodon and there are many options. Using Cloudflare is one option that has worked well for me. I encourage everyone that hosts a blog, either self-hosted or through some managed provider, to ensure that page caching and the oembed URL for WordPress is cached.