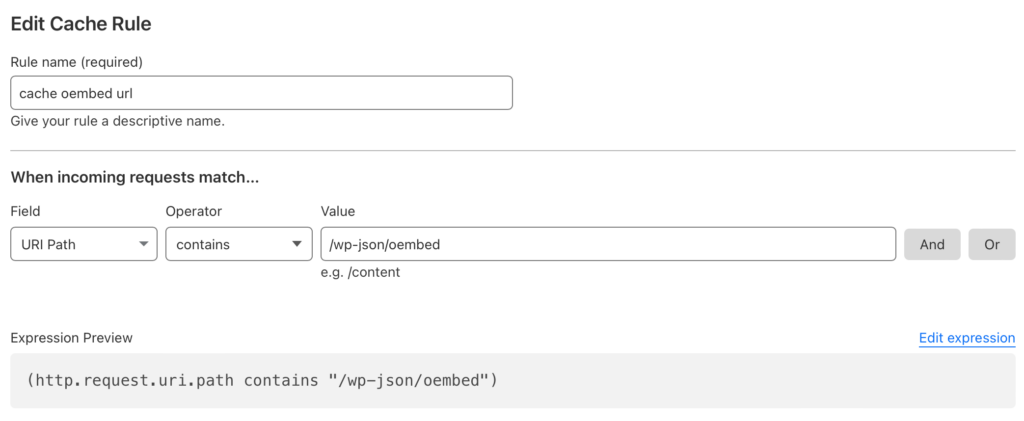
One thing I dislike in WordPress is that it makes numerous external http requests while in the admin. This happens even if you have disabled any auto update systems in wp-config.php and can cause small pauses while loading admin pages while you wait for the requests to finish. Since I manage my site through a Gitlab based CI/CD workflow, auto updates don’t make a lot of sense for me and I would prefer to not have WordPress core or themes phoning home and slowing down the admin experience.
There is an existing option for blocking http requests in WordPress and it presented as a pair of defines you can use to block all requests and then allow some. These defines are WP_HTTP_BLOCK_EXTERNAL and WP_ACCESSIBLE_HOSTS which are describe in more depth at https://developer.wordpress.org/reference/classes/wp_http/block_request/. This a great way to block requests and generally the way to do something like this, block everything and then allow what you want. However, for my situation there is a much smaller set of domains I want to block and then allow everything else. In other words, I want to do the opposite of what these defines can do you for you. This is because there are a number of external services I do want to interact with like Cloudflare and Mastodon.
What I came up with was an mu-plugin that reverses the logic of defines above. It is an almost 1:1 copy/paste of the code that is used to block some requests. I then define a list of domains I wish to block. The code is very simple:
<?php
function block_urls( $preempt, $parsed_args, $uri ) {
if ( ! defined( 'WP_BLOCKED_HOSTS' ) ) {
return false;
}
$check = parse_url( $uri );
if ( ! $check ) {
return false;
}
static $blocked_hosts = null;
static $wildcard_regex = array();
if ( null === $blocked_hosts ) {
$blocked_hosts = preg_split( '|,\s*|', WP_BLOCKED_HOSTS );
if ( false !== strpos( WP_BLOCKED_HOSTS, '*' ) ) {
$wildcard_regex = array();
foreach ( $blocked_hosts as $host ) {
$wildcard_regex[] = str_replace( '\*', '.+', preg_quote( $host, '/' ) );
}
$wildcard_regex = '/^(' . implode( '|', $wildcard_regex ) . ')$/i';
}
}
if ( ! empty( $wildcard_regex ) ) {
$results = preg_match( $wildcard_regex, $check['host'] );
if ($results > 0) {
error_log(sprintf("Blocking %s://%s%s", $check['scheme'], $check['host'], $check['path']));
} else {
error_log(sprintf("Allowing %s://%s%s", $check['scheme'], $check['host'], $check['path']));
}
return $results > 0;
} else {
$results = in_array( $check['host'], $blocked_hosts, true ); // Inverse logic, if it's in the array, then block it.
if ($results) {
error_log(sprintf("Blocking %s://%s%s", $check['scheme'], $check['host'], $check['path']));
} else {
error_log(sprintf("Allowing %s://%s%s", $check['scheme'], $check['host'], $check['path']));
}
return $results;
}
}
add_filter('pre_http_request', 'block_urls', 10, 3);With this code saved in your mu-plugins directory as blocked-urls.php, you can then add a define like this to block those URLs from being loaded by WordPress:
define( 'WP_BLOCKED_HOSTS', 'api.wordpress.org,themeisle.com,*.themeisle.com' );When WordPress attempts to load URLs from these domains, they will be blocked. You’ll also notice that this plugin is outputting all http requests that pass through WordPress core’s remote_get function. Using this information, you can block additional domains if you need to.